![[LinearRegression] 서울시 구별 CCTV현황 분석과 특성공학](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbRgE97%2FbtreXpevI03%2FiYFkOW63gihijzaR4bFqbk%2Fimg.jpg)

안녕하세요 코북입니다. 오늘은 머신러닝 기초 수업 때 사용했던 LinearRegression을 복습했습니다.
▶ 실습 목표
서울시 구별 CCTV 현황 분석
- pandas, matplotlib 사용하기
- 서울시 각 구별 CCTV 현황 살펴보기
- 인구 대비 CCTV 비율이 높거나 낮은 지역 알아보기
- 각 구별 CCTV 예측치 확인하고 그로부터 CCTV가 과하거나 부족한 지역 시각화
문제 풀이 흐름은 다음과 같습니다.
# 흐름
# 0. import
# 1. 파일 읽기 (csv, xml)
# 2. 정보 가공 - 틀린 컬럼명 바꿔주기, 필요한 컬럼들만 선택하기
# 3. 결측치 확인 후 삭제 - isnull(), boolean indexing
# 4. 오름차순, 내림차순 정렬 - sort_values()
# 5. 데이터 병합 - merge, unique()로 중복값 없애기
# 6. 특성공학 : 컬럼끼리 연산을 통해 의미 있는 컬럼을 만드는 작업 -> 시각화
# 7. 상관관계, 상관계수를 통해 예측값 구하기
# 8. 머신러닝 모델을 이용한 예측
# 9. 결과 시각화
0. 사용할 라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family = 'Malgun Gothic')1. csv파일 읽기 - 서울시 구별 CCTV 현황
# '파일명.확장자'
CCTV_Seoul = pd.read_csv('data/CCTV_in_Seoul.csv')
CCTV_Seoul.head() # .head(개수, default=5) -> 데이터를 원하는 만큼 보여줌
# 컬럼이름 바꾸기
CCTV_Seoul.rename(columns={"기관명" : "구"}, inplace =True)
# 결괏값만 나오고 바로 적용되지는 않는다
# inplace = True 를 사용하면 바꾼값을 저장해줌
CCTV_Seoul.head()
rename() 함수를 사용해 컬럼 이름을 적절하게 수정해줍니다.

2. 엑셀파일 읽기 - 서울시 인구 현황
pop_Seoul = pd.read_excel('data/population_in_Seoul.xls') # 필요없는 컬럼 많다
# header = 숫자 -> 읽고 싶은 row index 선택
# usecols = "column명" -> 읽고 싶은 column 선택
pop_Seoul = pd.read_excel('data/population_in_Seoul.xls', header = 2, usecols = "B, D, G, J, N")
pop_Seoul.head()
# 컬럼이름 바꾸기, list 이용
# pop_Seoul.columns 로 원래 컬럼 확인 후
pop_Seoul.columns = ['구','인구수','한국인수','외국인수','65세이상고령자수'] #를 통해 변경
pop_Seoul.head()
불필요한 컬럼이 많으면 필요한 컬럼들만 남기고 지워줍니다.

컬럼이름이 데이터의 내용과 맞지 않기 때문에 적절한 이름으로 바꿔줍니다. rename() 함수를 사용하기에는 바꿔야 하는 양이 많기 때문에 .columns를 통해 컬럼이름들을 바꿔줍니다.

3. 결측치 확인 (대략적인 데이터 확인 )
# .info()를 통해 대략적인 정보를 확인할 수 있다.
# 결측치, null 값 확인 가능
CCTV_Seoul.info()
pop_Seoul.info() # 27개의 entry가 있는데 26개만 non-null이다 -> 결측치 1개 있다
# 결측치 확인
# .isnull() -> 결측치에 대한 결과값을 True/False로 반환
# null 이면 True, non-null 이면 False
pop_Seoul['인구수'].isnull()
# boolean인덱싱
# -> True인 값만 인덱싱 해준다
# 내가 선택한 조건에 맞는 값만 보여줌 -> 조건 필터링!
pop_Seoul[pop_Seoul['인구수'].isnull()]
# 결측치 삭제
pop_Seoul.drop(26, inplace = True)
pop_Seoul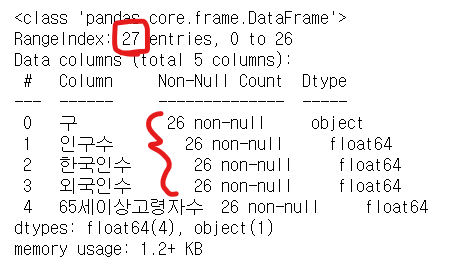
27 개의 entries 중 26개만 non-null이라고 나와있다. 결측치가 1개 존재한다는 뜻이다. 결측치가 하나 밖에 없기 때문에 drop() 함수를 사용해 지워주도록 합니다.
4. CCTV 수가 많은, 적은 지역을 파악해보자 (각각 5개 )
# 정렬하기
# .sort_values(by = '컬럼명', ascending = True, False)
# ascending = True -> 오름차순 (default)
# ascending = False -> 내림차순
CCTV_Seoul.sort_values(by = '소계', ascending= False).head() # 많은 지역 5개
CCTV_Seoul.sort_values(by = '소계').head() # 적은 지역 5개
CCTV_Seoul.sort_values(by = '소계', ascending= False).tail() # 적은 지역 5개

5. 데이터 병합
# 데이터 병합
# concat -> 그냥 붙인다
# merge -> 기준을 가지고 병합
CCTV_Seoul['구'].unique()
# 빠져있는 데이터 찾기
# 기준이 되는 컬럼을 정해 집합으로 만들어준다
# set() -> 집합으로 만들어준다
CCTV_구_set = set(CCTV_Seoul['구'].unique())
CCTV_구_set
pop_구_set = set(pop_Seoul['구'].unique())
pop_구_set
# 빠져있는 데이터 찾기
# 차집합 연산
pop_구_set - CCTV_구_set
CCTV_구_set - pop_구_set
# set() 이 결괏값 -> 없다는 뜻
# pd.merge()
# on = '컬럼명' -> 병합기준 컬럼
# tip ) shift + tab 누르면 함수 세부사항 확인가능
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on = '구') # how: str = 'inner' 가 디폴트 -> 겹치는 값만으로 합쳐줌
data_result.head()
6. 인구수 대비 CCTV 비율이 높은, 낮은 지역 알아보기
- 특성공학 : 컬럼끼리 연산을 통해 의미 있는 컬럼을 만드는 작업
data_result['인구수대비 CCTV비율'] = (data_result['소계']/data_result['인구수'])*100
data_result.head()
# 인구수 대비 CCTV가 많은 지역
data_result.sort_values(by = '인구수대비 CCTV비율', ascending=False).head()
# 인구수 대비 CCTV가 적은 지역
data_result.sort_values(by = '인구수대비 CCTV비율', ascending=False).tail()
# 시각화
gu = data_result.sort_values(by = '인구수대비 CCTV비율')['구']
per = data_result['인구수대비 CCTV비율'].sort_values()
plt.bar(gu,per)
plt.show()
# bar그래프 수평으로 보여주기
plt.figure(figsize=(10,7)) # .figure() -> 사이즈 조절
plt.barh(gu,per)
plt.xlabel('인구대비 CCTV비율')
plt.ylabel('구별')
plt.grid()
plt.show()


7. 각 구별 CCTV 예측 값을 만들어보자
- 상관관계, 상관계수를 확인해서 CCTV 설치 숫자와 관련된 컬럼을 알아보자
data_result.head()
# 구컬럼은 문자이기 때문에 상관관계 확인 불가능
# .set_index()
# 컬럼을 인덱스로 설정
# 구 컬럼을 인덱스로 설정
data_result.set_index('구', inplace = True)
data_result.head()
# 상관계수
data_result.corr()['소계']
#### 사용하기 부적합한 컬럼들
- 외국인수 '-0'에 가까운 약한 상관관계를 가짐
- 13, 14, 15, 16년 인구대비 CCTV 비율은 '소계'컬럼을 계산 혹은 활용한 컬럼
#### 적합한 컬럼들
- 인구수, 한국인수, 65세이상고령자수를 이용하자

8-1. 머신러닝 모델을 이용해 학습을 해보자
# import
from sklearn.linear_model import LinearRegression
# 머신러닝 모델 생성
model = LinearRegression()
X = data_result[['인구수','한국인수','65세이상고령자수']]
X # 학습용 문제
y = data_result['소계']
y # 학습용 정답
# 학습
model.fit(X, y)
# 예측
model.predict([[2000,1000,500]])
8-2. 각 구별로 CCTV 숫자를 예측해보자
# 예측값
CCTV_pre = model.predict(X)
CCTV_pre
# 예측값과 실제값의 차이(오차) 구하기
# y -> 실제값
error = np.abs(CCTV_pre - y) # np.abs() -> 절대값
error
9. 결과 시각화
data_result['인구수'][0]
data_result['소계'][0]
data_result.index
plt.figure(figsize = (14,10)) # 가로, 세로
plt.scatter(data_result['인구수'],
data_result['소계'],
s = 150, # s -> 점 크기
c = error) # c -> 오차값에 따라 컬러바꾸기 (실제값 - 예측값)
for i in range (25) :
plt.text(data_result['인구수'][i],
data_result['소계'][i],
data_result.index[i]) # .text(x축,y축, 글자) -> 글자 표시
plt.colorbar()
plt.xlabel('인구수')
plt.ylabel('CCTV 설치 수')
# plt.savefig('result.png') # 파일 추출해서 저장
plt.show()
배운 점
수업시간에 선생님을 따라가면서 코딩을 할 때는 내가 어떤 단계에서 어떤 작업을 하고 있는지 인지하기가 어려웠고, 왜 선형 회귀 모델을 사용하는지도 이해하지 못했었다. 하지만 이해가 안 되는 부분은 오히려 복습 하기 명확한 부분이기 때문에 오히려 좋은 결과를 불러온다. 머신러닝 작업 과정의 흐름과 선형 회귀 모델에 대한 이해를 중점으로 복습을 할 수 있는 시간이었다. 또한 특성 공학 부분은 내가 지난 Kaggle대회에서 거의 다루지 못했던 부분이었는데, 다시 한번 특성 공학에 대해 상기할 수 있었다.
'Machine Learning' 카테고리의 다른 글
| [LinearRegression] 선형 회귀 기초 (0) | 2021.09.14 |
|---|---|
| [Kaggle] 전자 상거래 물품 배송 예측(분류) (0) | 2021.09.10 |
| [MachineLearning] 머신러닝 개요 (0) | 2021.09.01 |
| [MachineLearning] 머신러닝과 기초통계학 (0) | 2021.08.31 |