[MSSQL] 커서 (CURSOR) 사용법
커서 (CURSOR)
mssql 명령어는 기본적으로 테이블에서 데이터를 처리할 때 집합 단위(Table)로 처리합니다. 하지만 특정 상황에 집합 단위가 아닌 행 단위(Row)로 데이터를 처리해야 하는 경우에 커서(CURSOR)를 이용하여 처리할 수 있습니다. 커서를 사용하면 테이블에서 여러 개의 행을 조회한 후 쿼리의 결과를 while 루프 안에서 한 행씩 처리해줍니다. 보통 DML(select, update, delete, insert)에서 사용됩니다.
커서의 특징
- 데이터를 집합 단위가 아닌 행 단위로 처리할 수 있어 주로 배치작업을 할 때 사용합니다.
- 집합 단위가 아닌 행 단위 작업 수행으로 처리 속도가 느리기 때문에 필요한 경우에만 사용하는 것이 좋습니다. 처리할 데이터가 적은 경우에는 문제가 되지 않지만 대량의 데이터를 처리하는 경우에는 성능 저하의 원인이 될 수 있습니다.
- DB 자체에서 반복 작업을 수행하기 때문에 웹에서의 처리가 필요 없으므로 웹 소스가 간결해집니다.
커서 명령어
DECLARE : 커서를 정의(선언)합니다.
DECLARE {cursor_name} CURSOR
FOR {select_statement}
-- {cusor_name} : 커서의 이름입니다.
-- {select_statement} : 커서의 결과 집합을 정의하는 SELECT 문입니다.
OPEN : 커서를 열고 선언한 커서에 지정된 SQL문을 실행하여 커서를 채웁니다. 커서가 결과 데이터셋의 첫 번째 행을 가리키도록 설정합니다.
OPEN { [GLOBAL] cursor_name}
-- GLOBAL이 지정된 경우 전역 커서를 참조하고,
-- 그렇지 않으면 로컬 커서를 참조합니다.
FETCH : 결과 데이터셋의 다음 행으로 커서를 이동합니다.
FETCH NEXT FROM {cursor_name} INTO @variable_name
-- NEXT : 현재 행 바로 다음에 오는 결과 행을 반환합니다. 커서에 대한 첫 번째 FETCH인 경우 첫 번째 행을 반환합니다.
-- INTO @varibale_name : 커서 선언 시 실행시켰던 {select_statement}의 데이터를 로컬 변수에 삽입합니다.
CLOSE : 수행 결과에 대한 처리 종료 시 커서를 닫습니다.
CLOSE { [GLOBAL] cursor_name}
DEALLOCATE : 커서 참조를 제거합니다. 마지막 커서 참조가 할당 해제되면 커서를 구성하는 데이터 구조가 SQL 서버에서 해제됩니다.
DEALLOCATE { [GLOBAL] cursor_name}
@@FETCH_STATUS : 이 함수는 현재 열려있는 커서에 대해 발행된 마지막 커서 FETCH문의 상태를 반환합니다.
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM {cursor_name} INTO @variable_name
END
-- 0 : FETCH 문 성공
-- -1 : FETCH 문 실패, 또는 행이 결과 세트를 벗어난 경우
-- -2 : 가져온 행이 없는 경우
-- -9 : 커서가 FETCH 작업을 수행하고 있지 않은 경우
※ 예시 코드의 구문은 요약된 내용으로 자세한 내용은 아래 링크를 참고하시길 바랍니다.
커서 실행 구조/메커니즘

쿼리의 결과인 행 집합을 커서가 한 행씩 읽어가면서 처리하고 처리가 끝나면 커서는 다음 행을 가리킵니다.
예제
1. 테이블 생성
CREATE TABLE DOG(
IDX INT IDENTITY(1,1) PRIMARY KEY,
NAME NVARCHAR(20),
AGE INT
)
INSERT INTO DOG(NAME,AGE)VALUES('타래',7)
INSERT INTO DOG(NAME,AGE)VALUES('단비',2)
INSERT INTO DOG(NAME,AGE)VALUES('보리',5)
INSERT INTO DOG(NAME,AGE)VALUES('콜라',11)
2-1. 커서문 실행
declare
@cnt int,
@name nvarchar(20),
@age int
set @cnt = 0;
declare cur cursor
for select name, age
from dog
open cur
fetch next from cur into @name, @age
while @@fetch_status = 0
begin
set @cnt = @cnt + 1;
update dog
set age = @age + 1
where name = @name
fetch next from cur into @name, @age
end
select @cnt as cnt
close cur
deallocate cur
2-2. 커서문 실행 (주석 있는 Ver)
-- 변수 선언
-- 조회한 컬럼을 담을 변수도 선언해야 한다
declare
@cnt int, -- 몇 회 실행 됐는지 체크하기 위한 변수
@name nvarchar(20),
@age int
-- 변수 초기화
set @cnt = 0;
-- 커서 선언
declare cur cursor
-- 쿼리 조회
for select name, age
from dog
-- 커서 오픈
open cur
-- 커서의 첫 번째 행 반환
-- select한 값을 @name, @age 변수에 넣는다
fetch next from cur into @name, @age
-- 커서를 이용하여 한 Row씩 읽음
-- 커서의 마지막 행이 될 때까지 반복 작업을 실행
while @@fetch_status = 0
-- 작업하고자 하는 내용 Start
begin
set @cnt = @cnt + 1; -- 실행 횟수 + 1
update dog
set age = @age + 1
where name = @name
-- 작업하고자 하는 내용 End
-- 커서의 다음 행 반환
fetch next from cur into @name, @age
end
-- 실행 횟수 조회
select @cnt as cnt
-- 커서 닫기
close cur
-- 커서 참조 제거 (초기화)
deallocate cur
3. 실행 결과
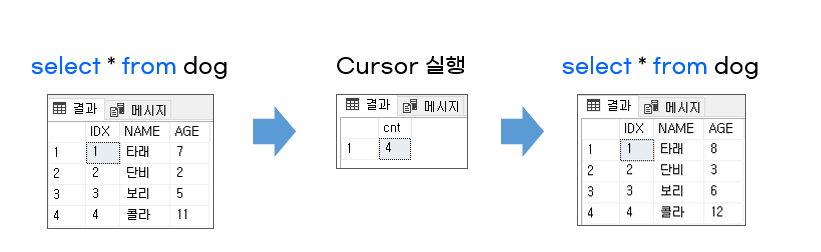
배운 점
최근 서로 다른 DB 간 데이터를 이동시키면서 커서를 사용할 일이 있었는데 문법이나 흐름이 잘 이해되지 않아서 커서에 대해 공부해봤습니다. 커서가 무엇인지, 커서는 어떤 메커니즘으로 실행되는지, 어떻게 사용하는지까지 종합적으로 이해할 수 있는 시간이었습니다. 하나 아쉬운 점은 언제 어떤 상황에서 커서를 사용하는지는 아직 정확하게 모르겠다는 점입니다. 좀 더 많은 경험이 필요해...